When to Self-Host LLMs vs. Use APIs
Decision framework for choosing between self-hosted models and API-based services based on volume, latency, privacy, and cost.
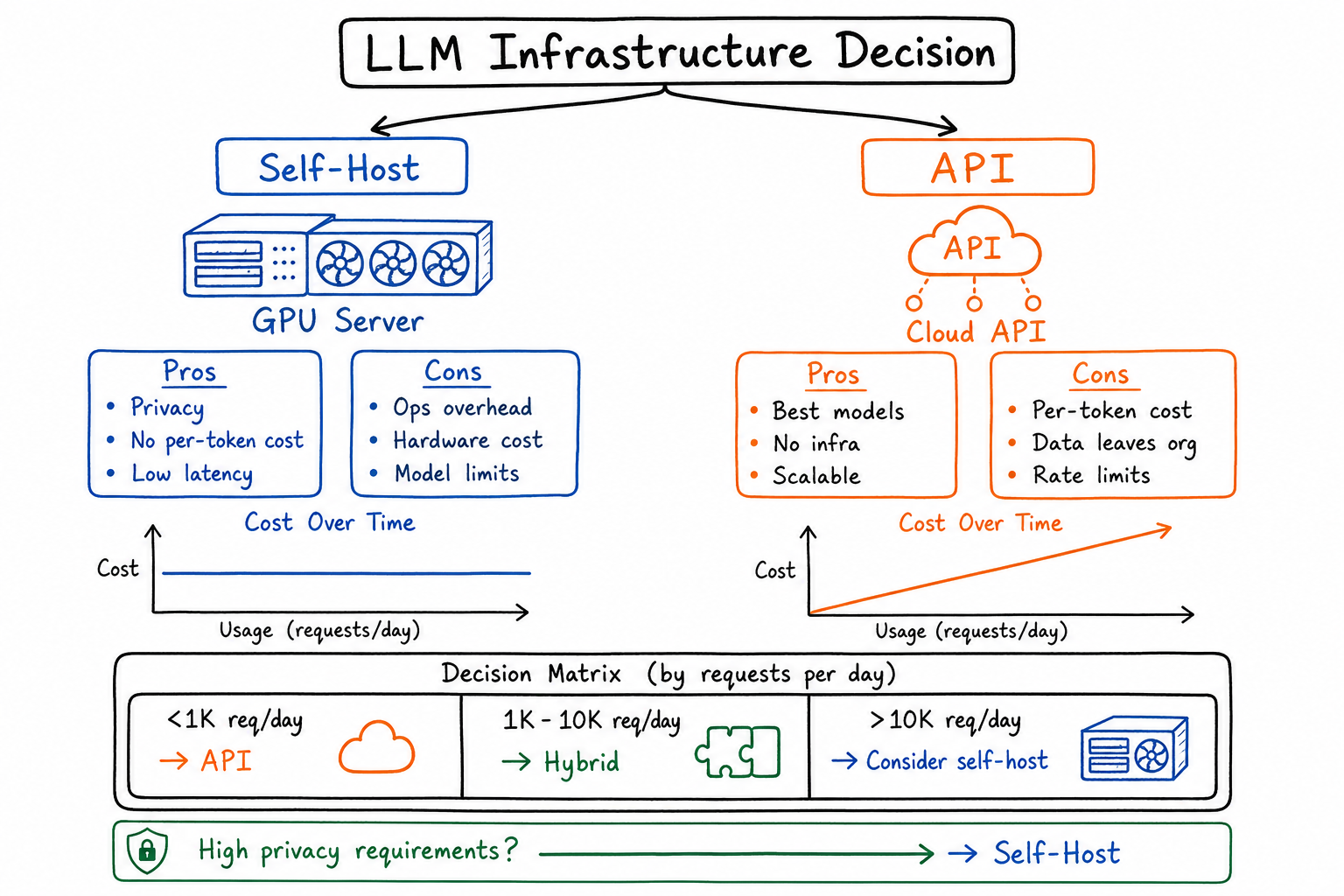
When to Self-Host LLMs vs. Use APIs
One of the most common questions in AI infrastructure today: “Should we run our own LLM or just use OpenAI?” After researching this extensively and running my own cost analyses, I’ve developed a decision framework that cuts through the hype and focuses on what actually matters for different situations.
The Build vs Buy Question for LLM Infrastructure
This isn’t a new dilemma—it’s the classic build vs buy decision, just with higher stakes. LLM infrastructure sits at the intersection of compute costs, model capabilities, and operational complexity. Get it wrong, and you’re either overpaying for API calls or drowning in GPU management headaches.
The answer is rarely absolute. Startups have wasted months building inference infrastructure they didn’t need, and enterprises have hemorrhaged money on API costs that would have paid for dedicated hardware in three months.
Let me walk you through how I think about this.
Cost Analysis: API Pricing vs Infrastructure Costs
Cost is usually the first thing people look at, and for good reason. But the math isn’t straightforward.
API Pricing (as of late 2025)
| Provider | Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|---|
| OpenAI | GPT-4o | $2.50 | $10.00 |
| OpenAI | GPT-4o-mini | $0.15 | $0.60 |
| Anthropic | Claude 3.5 Sonnet | $3.00 | $15.00 |
| Gemini 1.5 Pro | $1.25 | $5.00 |
Self-Hosting Costs (Monthly)
| Setup | Hardware | Power/Cooling | Personnel | Total Monthly |
|---|---|---|---|---|
| Single A100 (80GB) | ~$2,000 (amortized) | $200 | $500 (fractional) | ~$2,700 |
| 4x A100 Cluster | ~$8,000 (amortized) | $800 | $2,000 (fractional) | ~$10,800 |
| Cloud GPU (A100) | ~$3,500 (reserved) | Included | $500 | ~$4,000 |
| Cloud GPU (H100) | ~$5,500 (reserved) | Included | $500 | ~$6,000 |
The Crossover Point
Here’s where it gets interesting. Let me show you the monthly cost comparison at different usage levels, assuming a 70B parameter model self-hosted vs GPT-4o API:
| Monthly Tokens | API Cost (GPT-4o) | Self-Host (Cloud A100) | Winner |
|---|---|---|---|
| 10M | $75 | $4,000 | API |
| 100M | $750 | $4,000 | API |
| 500M | $3,750 | $4,000 | Roughly equal |
| 1B | $7,500 | $4,000 | Self-host |
| 5B | $37,500 | $8,000 (2x GPU) | Self-host |
| 10B+ | $75,000+ | $16,000 (4x GPU) | Self-host |
The crossover typically happens around 500M-1B tokens per month. Below that, APIs almost always win. Above that, self-hosting starts making financial sense—but only if you have the operational capacity.
Latency Considerations
Network latency is often underestimated. Let’s break it down:
API Latency Components
- Network round-trip: 50-150ms (varies by region)
- Queue time: 0-500ms (varies by load)
- Inference time: Model-dependent
- Response streaming: Mitigates perceived latency
Self-Hosted Latency
- Network round-trip: 1-10ms (internal network)
- Queue time: Depends on your infrastructure
- Inference time: Same as API (hardware-dependent)
When latency matters most:
- Real-time chat applications
- Interactive coding assistants
- Gaming NPCs
- Trading/financial applications
I had a client building a real-time translation feature. They were seeing 800ms+ response times with API calls. Moving to self-hosted inference on a nearby data center dropped that to under 200ms. For their use case, that difference was make-or-break.
When latency doesn’t matter:
- Batch processing
- Email generation
- Document summarization
- Async workflows
Privacy and Data Sovereignty
This is often the deciding factor for regulated industries.
When You Must Self-Host
- Healthcare (HIPAA): Patient data cannot leave your infrastructure without BAAs, and even then, some organizations won’t accept the risk
- Financial Services: Trading strategies, customer financial data, and proprietary models
- Government/Defense: Classified or sensitive information
- Legal: Attorney-client privileged information
- European Operations: GDPR compliance can be simpler with data that never leaves your infrastructure
What APIs Offer
Major providers now offer:
- SOC 2 Type II compliance
- HIPAA BAAs (Business Associate Agreements)
- Data processing agreements
- Zero data retention options
- Regional endpoints
But here’s the thing: even with all these protections, some data simply cannot touch third-party infrastructure. If your legal or compliance team says no, that’s your answer.
Model Quality Tradeoffs
Let’s be honest about where things stand.
Frontier Models (API-only)
- GPT-4o, Claude 3.5 Opus: Best reasoning, most capable
- Gemini Ultra: Strong multimodal capabilities
- These models have no open-source equivalents at the same capability level
Strong Open Source Options
- Llama 3.1 405B: Closest to GPT-4 class, requires significant hardware
- Llama 3.1 70B: Excellent balance of capability and efficiency
- Mixtral 8x22B: Great for instruction-following tasks
- Qwen 2.5 72B: Strong multilingual and coding capabilities
The Capability Gap
| Task | GPT-4 Class | Llama 70B | Gap |
|---|---|---|---|
| Complex reasoning | Excellent | Good | Noticeable |
| Code generation | Excellent | Very Good | Small |
| Creative writing | Excellent | Good | Moderate |
| Instruction following | Excellent | Very Good | Small |
| Factual accuracy | Good | Good | Minimal |
| Domain-specific (fine-tuned) | Good | Excellent | Open source wins |
Key insight: For domain-specific applications where you can fine-tune, open source models often outperform general-purpose APIs. I’ve seen fine-tuned Llama models beat GPT-4 on specific tasks by significant margins.
Operational Complexity of Self-Hosting
This is where I see the most underestimation. Self-hosting LLMs isn’t like running a web server.
What You Need
Infrastructure:
- GPU procurement and management
- CUDA/ROCm driver maintenance
- Networking for multi-GPU inference
- Storage for model weights (70B model = ~140GB)
- Monitoring and alerting
Expertise:
- ML engineering for optimization
- DevOps/SRE for reliability
- Security for model and data protection
Ongoing Work:
- Model updates and benchmarking
- Performance optimization
- Scaling and capacity planning
- Incident response
Realistic Team Requirements
| Scale | Minimum Team | Recommended Team |
|---|---|---|
| Single model, low traffic | 0.5 FTE ML Eng | 1 FTE + DevOps support |
| Production, moderate traffic | 1 FTE ML Eng, 0.5 DevOps | 2 FTE ML Eng, 1 DevOps |
| Multi-model, high traffic | 2+ FTE ML Eng, 1 DevOps | 4+ FTE ML Eng, 2 DevOps, 1 SRE |
Don’t have this capacity? APIs are your friend.
Hybrid Approaches
The best architectures I’ve designed often use both. Here’s how:
Pattern 1: Tiered by Complexity
- Simple queries → Self-hosted small model (Llama 8B)
- Medium complexity → Self-hosted large model (Llama 70B)
- Complex reasoning → GPT-4 API
Pattern 2: Tiered by Sensitivity
- Sensitive data → Self-hosted
- Non-sensitive data → API
Pattern 3: Development vs Production
- Development/testing → API (faster iteration)
- Production → Self-hosted (cost control)
Pattern 4: Burst Handling
- Baseline load → Self-hosted
- Traffic spikes → API overflow
One client runs 80% of their inference on self-hosted Llama 70B but routes complex edge cases to GPT-4. Their costs dropped 60% without sacrificing quality where it matters.
Decision Framework
Here’s my framework, distilled into concrete thresholds:
Choose APIs If:
- Monthly token usage < 500M
- You need frontier model capabilities (GPT-4 class reasoning)
- Your team lacks ML/GPU infrastructure expertise
- You’re still experimenting and iterating on prompts
- Time-to-market is critical
- Compliance allows third-party processing
Choose Self-Hosting If:
- Monthly token usage > 1B tokens
- Latency requirements < 200ms
- Data cannot leave your infrastructure (hard requirement)
- You have ML engineering capacity
- You need fine-tuned models for specific domains
- You’re running 24/7 production workloads
Consider Hybrid If:
- You have varying sensitivity levels in your data
- Traffic is spiky or unpredictable
- You need both frontier capabilities AND domain-specific performance
- You want to optimize costs while maintaining quality
Real-World Scenarios
Scenario 1: SaaS Startup (Choose API)
- 50M tokens/month
- Small engineering team
- Need to move fast
- Customer data has standard privacy requirements
Recommendation: Start with GPT-4o-mini for most tasks, GPT-4o for complex reasoning. Revisit when you hit 500M+ tokens/month.
Scenario 2: Healthcare Company (Choose Self-Host)
- 200M tokens/month
- Strict HIPAA requirements, risk-averse legal team
- Processing patient records and clinical notes
- Have budget for ML engineering hire
Recommendation: Self-host Llama 70B with proper fine-tuning on medical terminology. The compliance peace of mind is worth the operational overhead.
Scenario 3: E-commerce Platform (Choose Hybrid)
- 2B tokens/month
- Mix of product descriptions (not sensitive) and customer service (somewhat sensitive)
- Variable traffic with major spikes during sales
Recommendation: Self-hosted Llama for product content generation, API for customer service with human oversight, API burst capacity for traffic spikes.
Scenario 4: Financial Trading Firm (Choose Self-Host)
- 500M tokens/month
- Sub-100ms latency requirements
- Proprietary trading strategies in prompts
- Budget is secondary to performance and security
Recommendation: Self-hosted on premium hardware (H100s), multiple redundant deployments, no external dependencies.
Final Thoughts
The self-host vs API question doesn’t have a universal answer. What I can tell you is this: start with APIs unless you have a compelling reason not to. They’re the fastest path to value, and you can always migrate later.
But keep running the numbers. Set up monitoring on your token usage. The day your API bill hits $5,000/month, start planning your self-hosting infrastructure. By the time it hits $10,000, you should be ready to flip the switch.
The organizations that get this right treat it as an ongoing optimization problem, not a one-time decision. Your needs will change, the technology will evolve, and your infrastructure should adapt accordingly.