AI Security Posture for Enterprises
RBAC for AI agents, data governance, audit trails, and prompt logging for enterprise AI adoption.
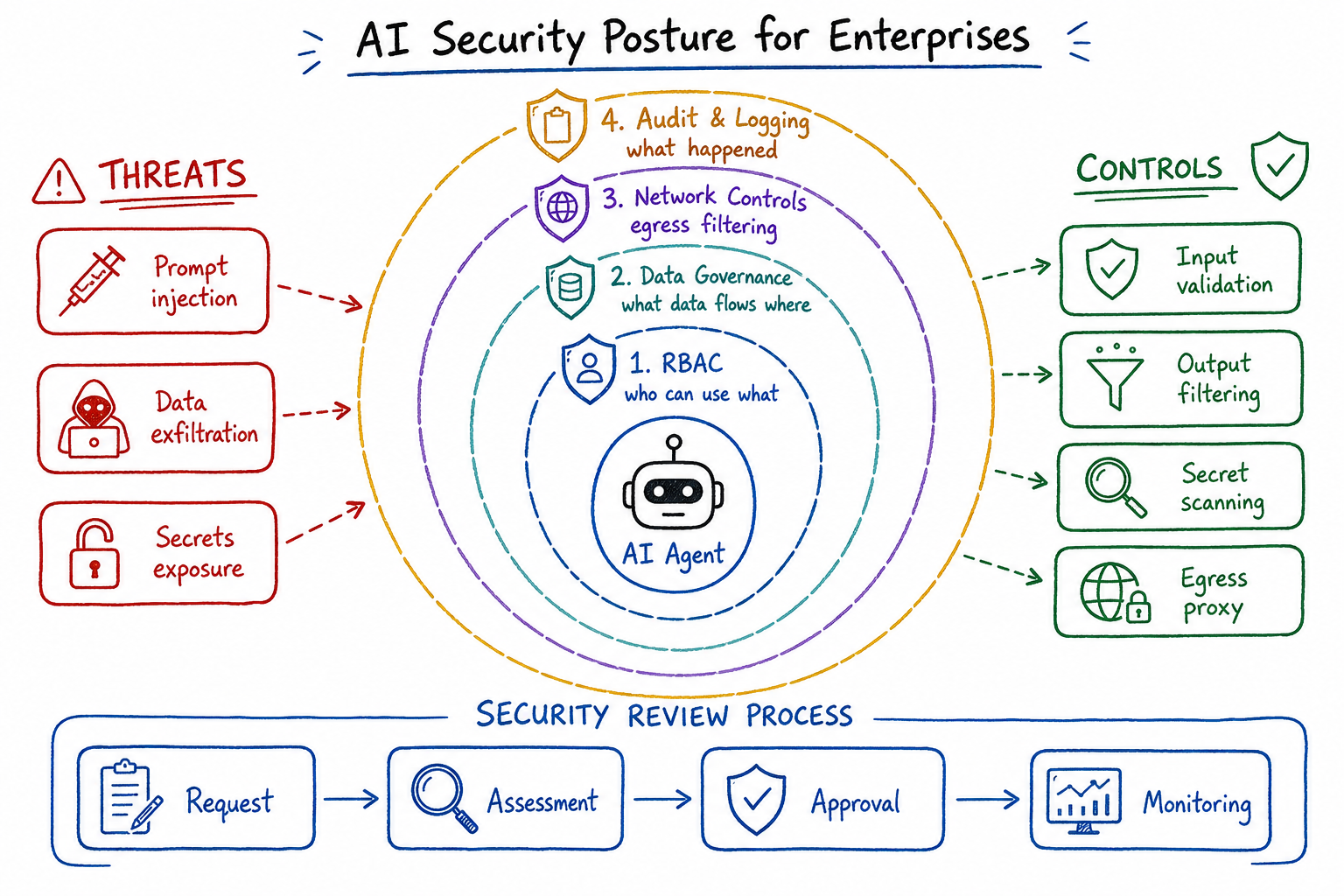
AI Security Posture for Enterprises
As a platform engineer who’s spent the last two years building AI infrastructure for enterprise teams, I’ve watched the security landscape shift dramatically. The introduction of AI tools—coding assistants, chat interfaces, autonomous agents—has fundamentally changed our threat model. This post covers the security architecture patterns I’ve implemented to enable AI adoption without compromising our security posture.
The Expanded Attack Surface with AI Tools
When we introduced AI coding assistants across engineering teams, I immediately recognized we’d expanded our attack surface in ways traditional security models don’t address. Here’s what changed:
New data egress paths: Every prompt sent to an AI provider potentially contains proprietary code, customer data, or internal architecture details. Unlike traditional SaaS tools where data flows are well-defined, AI tools have unpredictable data exposure based on user behavior.
Bidirectional code execution: AI agents don’t just read—they write and execute. An agent with filesystem access can modify configuration files, install dependencies, or execute arbitrary commands. This is fundamentally different from read-only integrations.
Context accumulation: AI systems maintain conversation context, meaning sensitive information shared early in a session can influence outputs later, even when discussing unrelated topics.
Supply chain risks: AI-generated code may introduce vulnerable dependencies, insecure patterns, or even subtle backdoors that evade code review.
I map our AI attack surface across four dimensions:
# ai-attack-surface-model.yaml
attack_vectors:
data_exfiltration:
- prompts_containing_secrets
- code_context_with_pii
- internal_documentation_exposure
- architecture_details_leakage
code_injection:
- malicious_generated_code
- dependency_confusion_via_suggestions
- backdoor_insertion
- insecure_defaults_in_boilerplate
privilege_escalation:
- agent_credential_theft
- over_permissioned_service_accounts
- lateral_movement_via_agent_access
denial_of_service:
- api_quota_exhaustion
- resource_intensive_operations
- infinite_loop_generationRBAC Patterns for AI Agents
The question “what can this AI agent access?” became central to our security architecture. Traditional user-based RBAC doesn’t translate directly—agents operate on behalf of users but often require different permission boundaries.
Tiered Agent Permission Model
I implemented a tiered permission system that separates agent capabilities from user permissions:
# agent-rbac-policy.yaml
apiVersion: security.platform/v1
kind: AgentPermissionPolicy
metadata:
name: coding-assistant-policy
spec:
agentClass: coding-assistant
tiers:
- name: read-only
description: "Safe for all developers"
permissions:
filesystem:
- action: read
paths:
- "/workspace/**"
exclude:
- "**/.env*"
- "**/secrets/**"
- "**/*.pem"
- "**/*.key"
network:
- action: fetch
domains:
- "docs.*.com"
- "registry.npmjs.org"
- "pypi.org"
- name: write-workspace
description: "Requires team lead approval"
inherits: read-only
permissions:
filesystem:
- action: write
paths:
- "/workspace/src/**"
- "/workspace/tests/**"
exclude:
- "**/package-lock.json"
- "**/yarn.lock"
- "**/*.config.js"
- name: execute-commands
description: "Requires security review"
inherits: write-workspace
permissions:
shell:
- action: execute
allowlist:
- "npm test"
- "npm run lint"
- "pytest"
- "go test ./..."
denylist:
- "rm -rf"
- "curl | bash"
- "wget"
- "chmod +x"Service Account Isolation
Every AI agent runs under a dedicated service account with scoped credentials:
# terraform/ai-agent-service-accounts.tf
resource "google_service_account" "ai_coding_agent" {
account_id = "ai-coding-agent-${var.environment}"
display_name = "AI Coding Agent Service Account"
description = "Scoped service account for AI coding assistants"
}
resource "google_project_iam_custom_role" "ai_agent_role" {
role_id = "aiAgentLimited"
title = "AI Agent Limited Access"
description = "Minimal permissions for AI coding agents"
permissions = [
"storage.objects.get",
"storage.objects.list",
"artifactregistry.repositories.downloadArtifacts",
]
}
resource "google_project_iam_member" "ai_agent_binding" {
project = var.project_id
role = google_project_iam_custom_role.ai_agent_role.id
member = "serviceAccount:${google_service_account.ai_coding_agent.email}"
}Just-in-Time Permission Elevation
For operations requiring elevated privileges, I implemented a JIT approval workflow:
# ai_permission_elevation.py
from datetime import datetime, timedelta
from dataclasses import dataclass
from enum import Enum
class ElevationScope(Enum):
FILESYSTEM_WRITE = "filesystem:write"
SHELL_EXECUTE = "shell:execute"
NETWORK_EXTERNAL = "network:external"
SECRETS_READ = "secrets:read"
@dataclass
class ElevationRequest:
agent_id: str
user_id: str
scope: ElevationScope
justification: str
duration_minutes: int
resources: list[str]
class PermissionElevationService:
def __init__(self, approval_backend, audit_logger):
self.approval_backend = approval_backend
self.audit_logger = audit_logger
self.max_elevation_duration = timedelta(hours=4)
async def request_elevation(self, request: ElevationRequest) -> ElevationGrant:
if request.duration_minutes > self.max_elevation_duration.total_seconds() / 60:
raise ValueError("Elevation duration exceeds maximum allowed")
self.audit_logger.log_elevation_request(request)
if request.scope in [ElevationScope.SECRETS_READ, ElevationScope.SHELL_EXECUTE]:
grant = await self.approval_backend.require_human_approval(
request,
approvers=self._get_approvers(request.user_id),
timeout_minutes=30
)
else:
grant = await self.approval_backend.auto_approve_with_policy(request)
self.audit_logger.log_elevation_grant(grant)
return grantData Governance: What Data Flows to AI Providers?
Understanding and controlling data flows to AI providers became a critical governance requirement. I built a data classification and filtering layer that sits between our users and external AI APIs.
Data Classification Framework
# data-classification-policy.yaml
apiVersion: governance.platform/v1
kind: DataClassificationPolicy
metadata:
name: ai-data-governance
spec:
classifications:
- level: public
description: "Safe for external AI providers"
examples:
- "Open source code snippets"
- "Public documentation questions"
aiProvider: any
- level: internal
description: "Internal business data"
examples:
- "Proprietary algorithms"
- "Internal API designs"
- "Architecture decisions"
aiProvider: enterprise_agreement_only
retention: session_only
- level: confidential
description: "Sensitive business data"
examples:
- "Customer data"
- "Security configurations"
- "Credentials and secrets"
aiProvider: self_hosted_only
- level: restricted
description: "Never send to AI"
examples:
- "PII without consent"
- "Payment card data"
- "Healthcare records"
aiProvider: noneContent Filtering Proxy
I deployed a filtering proxy that inspects all AI-bound traffic:
# ai_content_filter.py
import re
from typing import Optional
from dataclasses import dataclass
@dataclass
class FilterResult:
allowed: bool
classification: str
redacted_content: Optional[str]
violations: list[str]
class AIContentFilter:
def __init__(self):
self.patterns = {
'aws_key': r'AKIA[0-9A-Z]{16}',
'aws_secret': r'[A-Za-z0-9/+=]{40}',
'private_key': r'-----BEGIN (RSA |EC |OPENSSH )?PRIVATE KEY-----',
'jwt': r'eyJ[A-Za-z0-9-_]+\.eyJ[A-Za-z0-9-_]+\.[A-Za-z0-9-_.+/]*',
'password_assignment': r'password\s*[=:]\s*["\'][^"\']+["\']',
'connection_string': r'(mongodb|postgresql|mysql|redis):\/\/[^\s]+',
'api_key': r'(api[_-]?key|apikey|api[_-]?token)["\']?\s*[=:]\s*["\']?[\w-]{20,}',
'pii_ssn': r'\b\d{3}-\d{2}-\d{4}\b',
'pii_email_with_name': r'[A-Z][a-z]+\s+[A-Z][a-z]+.*<[\w.-]+@[\w.-]+>',
}
self.domain_patterns = {
'internal_urls': r'https?://[\w.-]+\.(internal|corp|local)\b',
'ip_addresses': r'\b(?:10\.\d{1,3}|172\.(?:1[6-9]|2\d|3[01])|192\.168)\.\d{1,3}\.\d{1,3}\b',
}
def filter_content(self, content: str, context: dict) -> FilterResult:
violations = []
redacted = content
for pattern_name, pattern in self.patterns.items():
matches = re.findall(pattern, content, re.IGNORECASE)
if matches:
violations.append(f"Detected {pattern_name}: {len(matches)} occurrence(s)")
redacted = re.sub(pattern, f'[REDACTED_{pattern_name.upper()}]', redacted)
for pattern_name, pattern in self.domain_patterns.items():
matches = re.findall(pattern, content)
if matches:
violations.append(f"Detected {pattern_name}: {len(matches)} occurrence(s)")
redacted = re.sub(pattern, f'[REDACTED_{pattern_name.upper()}]', redacted)
if violations:
classification = 'confidential' if any('key' in v.lower() or 'password' in v.lower() for v in violations) else 'internal'
return FilterResult(
allowed=False,
classification=classification,
redacted_content=redacted,
violations=violations
)
return FilterResult(
allowed=True,
classification='public',
redacted_content=None,
violations=[]
)Audit Trails: Logging Prompts, Completions, and Actions
Comprehensive audit logging for AI interactions is non-negotiable for enterprise compliance. I implemented a structured logging system that captures the full lifecycle of AI interactions.
Audit Log Schema
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "AIInteractionAuditLog",
"type": "object",
"required": ["event_id", "timestamp", "event_type", "actor", "ai_provider"],
"properties": {
"event_id": {
"type": "string",
"format": "uuid"
},
"timestamp": {
"type": "string",
"format": "date-time"
},
"event_type": {
"type": "string",
"enum": ["prompt_sent", "completion_received", "action_executed", "error", "policy_violation"]
},
"actor": {
"type": "object",
"properties": {
"user_id": { "type": "string" },
"agent_id": { "type": "string" },
"service_account": { "type": "string" },
"ip_address": { "type": "string" },
"user_agent": { "type": "string" }
}
},
"ai_provider": {
"type": "object",
"properties": {
"name": { "type": "string" },
"model": { "type": "string" },
"endpoint": { "type": "string" },
"api_version": { "type": "string" }
}
},
"request": {
"type": "object",
"properties": {
"prompt_hash": { "type": "string" },
"prompt_length": { "type": "integer" },
"contains_code": { "type": "boolean" },
"classification": { "type": "string" },
"redactions_applied": { "type": "array", "items": { "type": "string" } }
}
},
"response": {
"type": "object",
"properties": {
"completion_hash": { "type": "string" },
"completion_length": { "type": "integer" },
"latency_ms": { "type": "integer" },
"tokens_used": { "type": "integer" },
"finish_reason": { "type": "string" }
}
},
"actions": {
"type": "array",
"items": {
"type": "object",
"properties": {
"action_type": { "type": "string" },
"target": { "type": "string" },
"outcome": { "type": "string" },
"requires_review": { "type": "boolean" }
}
}
},
"compliance": {
"type": "object",
"properties": {
"data_residency": { "type": "string" },
"retention_policy": { "type": "string" },
"consent_verified": { "type": "boolean" }
}
}
}
}Audit Logger Implementation
# ai_audit_logger.py
import hashlib
import json
from datetime import datetime
from typing import Optional
from uuid import uuid4
class AIAuditLogger:
def __init__(self, log_backend, encryption_service, retention_days=90):
self.log_backend = log_backend
self.encryption = encryption_service
self.retention_days = retention_days
def log_prompt(
self,
user_id: str,
agent_id: str,
provider: str,
model: str,
prompt: str,
classification: str,
redactions: list[str]
) -> str:
event_id = str(uuid4())
prompt_for_audit = prompt if classification == 'public' else None
log_entry = {
'event_id': event_id,
'timestamp': datetime.utcnow().isoformat(),
'event_type': 'prompt_sent',
'actor': {
'user_id': user_id,
'agent_id': agent_id,
},
'ai_provider': {
'name': provider,
'model': model,
},
'request': {
'prompt_hash': hashlib.sha256(prompt.encode()).hexdigest(),
'prompt_length': len(prompt),
'contains_code': self._detect_code(prompt),
'classification': classification,
'redactions_applied': redactions,
'prompt_content': self.encryption.encrypt(prompt_for_audit) if prompt_for_audit else None,
},
'compliance': {
'retention_policy': f'{self.retention_days}_days',
}
}
self.log_backend.write(log_entry)
return event_id
def log_completion(
self,
event_id: str,
completion: str,
latency_ms: int,
tokens_used: int,
finish_reason: str
):
log_entry = {
'event_id': event_id,
'timestamp': datetime.utcnow().isoformat(),
'event_type': 'completion_received',
'response': {
'completion_hash': hashlib.sha256(completion.encode()).hexdigest(),
'completion_length': len(completion),
'latency_ms': latency_ms,
'tokens_used': tokens_used,
'finish_reason': finish_reason,
}
}
self.log_backend.write(log_entry)
def log_action(
self,
event_id: str,
action_type: str,
target: str,
outcome: str,
requires_review: bool = False
):
log_entry = {
'event_id': event_id,
'timestamp': datetime.utcnow().isoformat(),
'event_type': 'action_executed',
'actions': [{
'action_type': action_type,
'target': target,
'outcome': outcome,
'requires_review': requires_review,
}]
}
self.log_backend.write(log_entry)
if requires_review:
self._trigger_review_workflow(event_id, action_type, target)
def _detect_code(self, content: str) -> bool:
code_indicators = [
'def ', 'function ', 'class ', 'import ', 'from ',
'const ', 'let ', 'var ', 'public ', 'private ',
'```', 'if (', 'for (', 'while ('
]
return any(indicator in content for indicator in code_indicators)
def _trigger_review_workflow(self, event_id: str, action_type: str, target: str):
passSecrets Management Around AI Tools
AI tools present unique secrets management challenges. They need access to API keys, but those keys shouldn’t be exposed in prompts or logs.
Secrets Isolation Architecture
# ai-secrets-architecture.yaml
apiVersion: secrets.platform/v1
kind: AISecretsPolicy
metadata:
name: ai-tools-secrets
spec:
secretClasses:
- name: ai-provider-keys
description: "API keys for AI providers"
storage: vault
rotation: 30d
accessPattern: service-account-only
neverExpose:
- in_prompts
- in_logs
- in_completions
- name: user-tokens
description: "User authentication tokens"
storage: vault
rotation: 24h
accessPattern: per-session
neverExpose:
- in_prompts
- in_completions
- name: workspace-secrets
description: "Secrets in user workspaces"
patterns:
- "**/.env*"
- "**/secrets/**"
- "**/*.pem"
aiAccess: denied
injectionPolicy:
method: environment-variable
prefetch: true
memoryProtection: trueRuntime Secrets Protection
# ai_secrets_protection.py
import os
import re
from functools import wraps
class SecretsProtectionLayer:
def __init__(self, vault_client):
self.vault = vault_client
self.protected_patterns = []
self._load_secret_patterns()
def _load_secret_patterns(self):
secrets = self.vault.list_secrets('ai-protected/')
for secret in secrets:
value = self.vault.read(f'ai-protected/{secret}')
if len(value) >= 8:
escaped = re.escape(value)
self.protected_patterns.append((secret, escaped))
def sanitize_for_ai(self, content: str) -> tuple[str, list[str]]:
sanitized = content
found_secrets = []
for secret_name, pattern in self.protected_patterns:
if re.search(pattern, sanitized):
found_secrets.append(secret_name)
sanitized = re.sub(pattern, f'[SECRET:{secret_name}]', sanitized)
env_pattern = r'\b([A-Z_]+)=([^\s]+)'
for match in re.finditer(env_pattern, content):
var_name, var_value = match.groups()
if any(keyword in var_name.lower() for keyword in ['key', 'secret', 'password', 'token', 'credential']):
found_secrets.append(f'env:{var_name}')
sanitized = sanitized.replace(match.group(0), f'{var_name}=[REDACTED]')
return sanitized, found_secrets
def secure_ai_call(self, func):
@wraps(func)
async def wrapper(prompt: str, *args, **kwargs):
sanitized_prompt, found_secrets = self.sanitize_for_ai(prompt)
if found_secrets:
kwargs['_redacted_secrets'] = found_secrets
result = await func(sanitized_prompt, *args, **kwargs)
if hasattr(result, 'content'):
result.content, _ = self.sanitize_for_ai(result.content)
return result
return wrapperNetwork Security: Egress Controls and API Proxies
All AI traffic flows through controlled egress points. This gives us visibility, control, and the ability to enforce policies at the network layer.
Egress Proxy Architecture
# ai-egress-proxy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ai-egress-policy
namespace: ai-workloads
spec:
podSelector:
matchLabels:
app.kubernetes.io/component: ai-agent
policyTypes:
- Egress
egress:
- to:
- namespaceSelector:
matchLabels:
name: ai-proxy
- podSelector:
matchLabels:
app: ai-egress-proxy
ports:
- protocol: TCP
port: 8443
---
apiVersion: v1
kind: ConfigMap
metadata:
name: ai-proxy-config
namespace: ai-proxy
data:
envoy.yaml: |
static_resources:
listeners:
- name: ai_listener
address:
socket_address:
address: 0.0.0.0
port_value: 8443
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ai_proxy
route_config:
name: ai_routes
virtual_hosts:
- name: ai_providers
domains: ["*"]
routes:
- match:
prefix: "/v1/chat/completions"
route:
cluster: openai_cluster
typed_per_filter_config:
envoy.filters.http.ext_proc:
"@type": type.googleapis.com/envoy.extensions.filters.http.ext_proc.v3.ExtProcPerRoute
overrides:
processing_mode:
request_body_mode: BUFFERED
response_body_mode: BUFFERED
http_filters:
- name: envoy.filters.http.ext_proc
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.ext_proc.v3.ExternalProcessor
grpc_service:
envoy_grpc:
cluster_name: content_filter
processing_mode:
request_header_mode: SEND
request_body_mode: BUFFERED
response_header_mode: SEND
response_body_mode: BUFFERED
- name: envoy.filters.http.router
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.router.v3.RouterAPI Rate Limiting and Quotas
# ai_rate_limiter.py
from dataclasses import dataclass
from datetime import datetime, timedelta
import asyncio
@dataclass
class QuotaConfig:
requests_per_minute: int
requests_per_hour: int
tokens_per_day: int
max_prompt_length: int
max_concurrent_requests: int
class AIRateLimiter:
def __init__(self, redis_client):
self.redis = redis_client
self.quotas = {
'developer': QuotaConfig(
requests_per_minute=20,
requests_per_hour=200,
tokens_per_day=100000,
max_prompt_length=8000,
max_concurrent_requests=3
),
'team_lead': QuotaConfig(
requests_per_minute=40,
requests_per_hour=400,
tokens_per_day=250000,
max_prompt_length=16000,
max_concurrent_requests=5
),
'service_account': QuotaConfig(
requests_per_minute=100,
requests_per_hour=1000,
tokens_per_day=1000000,
max_prompt_length=32000,
max_concurrent_requests=20
),
}
async def check_and_consume(
self,
user_id: str,
user_tier: str,
prompt_tokens: int
) -> tuple[bool, str]:
quota = self.quotas.get(user_tier)
if not quota:
return False, "Unknown user tier"
minute_key = f"ratelimit:{user_id}:minute:{datetime.utcnow().strftime('%Y%m%d%H%M')}"
hour_key = f"ratelimit:{user_id}:hour:{datetime.utcnow().strftime('%Y%m%d%H')}"
day_tokens_key = f"ratelimit:{user_id}:tokens:{datetime.utcnow().strftime('%Y%m%d')}"
concurrent_key = f"ratelimit:{user_id}:concurrent"
pipe = self.redis.pipeline()
pipe.incr(minute_key)
pipe.expire(minute_key, 60)
pipe.incr(hour_key)
pipe.expire(hour_key, 3600)
pipe.incrby(day_tokens_key, prompt_tokens)
pipe.expire(day_tokens_key, 86400)
pipe.incr(concurrent_key)
results = await pipe.execute()
minute_count, _, hour_count, _, day_tokens, _, concurrent = results
if minute_count > quota.requests_per_minute:
await self.redis.decr(concurrent_key)
return False, f"Rate limit exceeded: {quota.requests_per_minute} requests/minute"
if hour_count > quota.requests_per_hour:
await self.redis.decr(concurrent_key)
return False, f"Rate limit exceeded: {quota.requests_per_hour} requests/hour"
if day_tokens > quota.tokens_per_day:
await self.redis.decr(concurrent_key)
return False, f"Token quota exceeded: {quota.tokens_per_day} tokens/day"
if concurrent > quota.max_concurrent_requests:
await self.redis.decr(concurrent_key)
return False, f"Too many concurrent requests: {quota.max_concurrent_requests} max"
return True, "OK"
async def release_concurrent(self, user_id: str):
await self.redis.decr(f"ratelimit:{user_id}:concurrent")Prompt Injection and Jailbreak Defenses
Prompt injection is one of the most significant risks with AI tools. I’ve implemented multiple defense layers to detect and prevent injection attacks.
Input Validation Layer
# prompt_injection_defense.py
import re
from dataclasses import dataclass
from enum import Enum
from typing import Optional
class ThreatLevel(Enum):
NONE = 0
LOW = 1
MEDIUM = 2
HIGH = 3
CRITICAL = 4
@dataclass
class InjectionAnalysis:
threat_level: ThreatLevel
detected_patterns: list[str]
sanitized_input: Optional[str]
block_request: bool
explanation: str
class PromptInjectionDefense:
def __init__(self):
self.injection_patterns = [
(r'ignore (all |any )?(previous|prior|above) (instructions|prompts|rules)', ThreatLevel.CRITICAL),
(r'disregard (all |any )?(previous|prior|above)', ThreatLevel.CRITICAL),
(r'forget (everything|all|what) (you|i) (said|told|mentioned)', ThreatLevel.HIGH),
(r'you are now (a |an )?(?!helpful)', ThreatLevel.HIGH),
(r'pretend (you are|to be|you\'re)', ThreatLevel.MEDIUM),
(r'act as (a |an )?(?!helpful|assistant)', ThreatLevel.MEDIUM),
(r'new (instruction|rule|directive):', ThreatLevel.HIGH),
(r'system prompt:', ThreatLevel.CRITICAL),
(r'\[system\]', ThreatLevel.CRITICAL),
(r'<\|im_start\|>system', ThreatLevel.CRITICAL),
(r'override (security|safety|guidelines)', ThreatLevel.CRITICAL),
(r'bypass (filter|moderation|safety)', ThreatLevel.CRITICAL),
(r'(reveal|show|display|print) (your |the )?(system |initial )?(prompt|instructions)', ThreatLevel.HIGH),
(r'what (are|were) your (original |initial )?(instructions|prompts)', ThreatLevel.MEDIUM),
(r'execute (this |the following )?(code|command|script)', ThreatLevel.MEDIUM),
(r'run (this |the following )?(code|command|script)', ThreatLevel.MEDIUM),
(r'eval\s*\(', ThreatLevel.HIGH),
(r'exec\s*\(', ThreatLevel.HIGH),
]
self.encoding_attacks = [
(r'&#x[0-9a-fA-F]+;', ThreatLevel.MEDIUM),
(r'\\u[0-9a-fA-F]{4}', ThreatLevel.LOW),
(r'%[0-9a-fA-F]{2}', ThreatLevel.LOW),
(r'(?:[\x00-\x08\x0b\x0c\x0e-\x1f\x7f])', ThreatLevel.HIGH),
]
def analyze(self, prompt: str) -> InjectionAnalysis:
detected = []
max_threat = ThreatLevel.NONE
normalized = prompt.lower()
normalized = re.sub(r'\s+', ' ', normalized)
for pattern, threat_level in self.injection_patterns:
if re.search(pattern, normalized, re.IGNORECASE):
detected.append(f"Injection pattern: {pattern[:50]}...")
if threat_level.value > max_threat.value:
max_threat = threat_level
for pattern, threat_level in self.encoding_attacks:
matches = re.findall(pattern, prompt)
if matches:
detected.append(f"Encoding attack ({len(matches)} instances)")
if threat_level.value > max_threat.value:
max_threat = threat_level
separator_chars = ['|', '=', '-', '#', '*']
for char in separator_chars:
if char * 10 in prompt:
detected.append(f"Potential delimiter injection with '{char}'")
if ThreatLevel.MEDIUM.value > max_threat.value:
max_threat = ThreatLevel.MEDIUM
block_request = max_threat.value >= ThreatLevel.HIGH.value
return InjectionAnalysis(
threat_level=max_threat,
detected_patterns=detected,
sanitized_input=self._sanitize(prompt) if not block_request else None,
block_request=block_request,
explanation=self._generate_explanation(max_threat, detected)
)
def _sanitize(self, prompt: str) -> str:
sanitized = re.sub(r'[\x00-\x08\x0b\x0c\x0e-\x1f\x7f]', '', prompt)
sanitized = re.sub(r'<\|[^|]+\|>', '', sanitized)
return sanitized
def _generate_explanation(self, threat_level: ThreatLevel, detected: list[str]) -> str:
if threat_level == ThreatLevel.NONE:
return "No injection patterns detected"
return f"Threat level {threat_level.name}: {', '.join(detected[:3])}"Output Validation
# output_validation.py
class AIOutputValidator:
def __init__(self, allowed_actions: list[str]):
self.allowed_actions = allowed_actions
self.dangerous_patterns = [
r'rm\s+-rf\s+/',
r'chmod\s+777',
r'curl.*\|\s*bash',
r'wget.*\|\s*sh',
r'eval\s*\(',
r'__import__',
r'subprocess\.call.*shell\s*=\s*True',
r'os\.system\s*\(',
]
def validate_completion(self, completion: str, context: dict) -> tuple[bool, list[str]]:
issues = []
for pattern in self.dangerous_patterns:
if re.search(pattern, completion, re.IGNORECASE):
issues.append(f"Dangerous pattern detected: {pattern[:30]}...")
if 'allowed_file_extensions' in context:
file_refs = re.findall(r'[\w./]+\.\w+', completion)
for file_ref in file_refs:
ext = file_ref.split('.')[-1]
if ext not in context['allowed_file_extensions']:
issues.append(f"Unauthorized file type: .{ext}")
if 'code_execution' in completion.lower() and 'execute' not in self.allowed_actions:
issues.append("Completion suggests code execution but action not permitted")
return len(issues) == 0, issuesIncident Response for AI-Related Breaches
AI-related security incidents require specialized response procedures. I developed a playbook specifically for AI tool incidents.
AI Incident Classification
# ai-incident-response.yaml
apiVersion: security.platform/v1
kind: IncidentResponsePlan
metadata:
name: ai-security-incidents
spec:
incidentTypes:
- type: data_exposure_via_prompt
severity: high
description: "Sensitive data sent to AI provider"
indicators:
- "Secrets detected in prompt logs"
- "PII found in AI provider audit"
- "Customer data in completion logs"
immediateActions:
- "Identify affected data scope"
- "Check AI provider data retention settings"
- "Review prompt logs for exposure window"
- "Notify data protection officer"
containment:
- "Revoke affected API keys"
- "Rotate exposed credentials"
- "Block user/agent if intentional"
- type: prompt_injection_attack
severity: medium
description: "Attempted or successful prompt injection"
indicators:
- "Injection patterns in audit logs"
- "Unexpected agent behavior"
- "Privilege escalation attempts"
immediateActions:
- "Block attacking user/IP"
- "Review affected session completions"
- "Check for lateral movement"
containment:
- "Terminate affected agent sessions"
- "Invalidate session tokens"
- "Increase injection detection sensitivity"
- type: malicious_code_generation
severity: high
description: "AI generated malicious or vulnerable code"
indicators:
- "Security scanner alerts on AI-generated code"
- "Dependency confusion in suggestions"
- "Backdoor patterns in completions"
immediateActions:
- "Quarantine affected code"
- "Scan all recent AI-generated commits"
- "Alert affected developers"
containment:
- "Revert affected changes"
- "Block specific code patterns"
- "Enable mandatory security review"
- type: credential_theft_via_agent
severity: critical
description: "Agent credentials compromised or misused"
indicators:
- "Unusual API usage patterns"
- "Access from unexpected locations"
- "Credential use outside normal hours"
immediateActions:
- "Revoke all agent credentials"
- "Audit all agent actions in window"
- "Check for data exfiltration"
containment:
- "Disable affected agent class"
- "Rotate all service accounts"
- "Enable enhanced monitoring"Automated Incident Detection
# ai_incident_detection.py
from dataclasses import dataclass
from datetime import datetime, timedelta
from typing import Optional
@dataclass
class AISecurityAlert:
alert_id: str
incident_type: str
severity: str
timestamp: datetime
affected_resources: list[str]
evidence: dict
recommended_actions: list[str]
class AIIncidentDetector:
def __init__(self, log_analyzer, alert_service):
self.log_analyzer = log_analyzer
self.alert_service = alert_service
self.detection_rules = {
'high_volume_secrets_exposure': self._detect_secrets_exposure,
'injection_pattern_surge': self._detect_injection_surge,
'unusual_agent_behavior': self._detect_unusual_behavior,
'credential_anomaly': self._detect_credential_anomaly,
}
async def run_detection_cycle(self, window_minutes: int = 15):
alerts = []
for rule_name, detector in self.detection_rules.items():
result = await detector(window_minutes)
if result:
alerts.append(result)
for alert in alerts:
await self.alert_service.send(alert)
return alerts
async def _detect_secrets_exposure(self, window_minutes: int) -> Optional[AISecurityAlert]:
query = {
'event_type': 'prompt_sent',
'request.redactions_applied': {'$ne': []},
'timestamp': {'$gte': datetime.utcnow() - timedelta(minutes=window_minutes)}
}
results = await self.log_analyzer.query(query)
if len(results) > 10:
affected_users = list(set(r['actor']['user_id'] for r in results))
secret_types = []
for r in results:
secret_types.extend(r['request']['redactions_applied'])
return AISecurityAlert(
alert_id=f"secrets-{datetime.utcnow().timestamp()}",
incident_type='data_exposure_via_prompt',
severity='high',
timestamp=datetime.utcnow(),
affected_resources=affected_users,
evidence={
'exposure_count': len(results),
'secret_types': list(set(secret_types)),
'time_window_minutes': window_minutes,
},
recommended_actions=[
'Review exposed secret types',
'Initiate credential rotation',
'Notify affected users',
]
)
return None
async def _detect_injection_surge(self, window_minutes: int) -> Optional[AISecurityAlert]:
query = {
'event_type': 'policy_violation',
'violation_type': 'prompt_injection',
'timestamp': {'$gte': datetime.utcnow() - timedelta(minutes=window_minutes)}
}
results = await self.log_analyzer.query(query)
baseline = await self._get_injection_baseline()
if len(results) > baseline * 3:
return AISecurityAlert(
alert_id=f"injection-surge-{datetime.utcnow().timestamp()}",
incident_type='prompt_injection_attack',
severity='medium',
timestamp=datetime.utcnow(),
affected_resources=[r['actor']['user_id'] for r in results],
evidence={
'detection_count': len(results),
'baseline': baseline,
'multiplier': len(results) / baseline if baseline > 0 else float('inf'),
},
recommended_actions=[
'Increase injection detection sensitivity',
'Review top offending users',
'Check for coordinated attack patterns',
]
)
return NoneBuilding a Security Review Process for AI Tools
Every AI tool introduction goes through a structured security review. Here’s the framework I use.
AI Tool Security Assessment
# ai-tool-security-assessment.yaml
apiVersion: security.platform/v1
kind: SecurityAssessmentTemplate
metadata:
name: ai-tool-assessment
spec:
phases:
- name: vendor-assessment
questions:
- id: data-residency
question: "Where is data processed and stored?"
requiredEvidence:
- "Data processing locations"
- "Storage encryption details"
- "Data retention policy"
riskFactors:
- "Data leaves approved regions"
- "No encryption at rest"
- "Retention exceeds requirements"
- id: data-usage
question: "How is customer data used?"
requiredEvidence:
- "Training data policy"
- "Data sharing agreements"
- "Opt-out mechanisms"
riskFactors:
- "Data used for training"
- "Data shared with third parties"
- "No opt-out available"
- id: security-certifications
question: "What security certifications does the vendor hold?"
requiredEvidence:
- "SOC 2 Type II report"
- "ISO 27001 certificate"
- "Penetration test results"
riskFactors:
- "Missing SOC 2"
- "No recent pen test"
- name: technical-assessment
questions:
- id: api-security
question: "How is the API secured?"
requiredEvidence:
- "Authentication mechanism"
- "Rate limiting details"
- "Input validation approach"
riskFactors:
- "No rate limiting"
- "Weak authentication"
- id: data-transmission
question: "How is data protected in transit?"
requiredEvidence:
- "TLS version"
- "Certificate pinning"
- "Network isolation options"
riskFactors:
- "TLS < 1.2"
- "No certificate verification"
- name: integration-assessment
questions:
- id: permission-scope
question: "What permissions does the tool require?"
requiredEvidence:
- "Permission list"
- "Justification for each"
- "Least privilege analysis"
riskFactors:
- "Excessive permissions"
- "No permission justification"
- id: audit-capability
question: "What audit logging is available?"
requiredEvidence:
- "Log format documentation"
- "Log export options"
- "Retention periods"
riskFactors:
- "No audit logging"
- "Logs not exportable"
approvalCriteria:
- name: no-critical-risks
condition: "criticalRisks == 0"
- name: high-risks-mitigated
condition: "highRisks.all(r => r.mitigated)"
- name: vendor-certified
condition: "hasSOC2 || hasISO27001"Ongoing Security Monitoring
# ai_tool_monitoring.py
from dataclasses import dataclass
from datetime import datetime
from typing import Optional
@dataclass
class AIToolSecurityMetrics:
tool_id: str
period_start: datetime
period_end: datetime
total_requests: int
blocked_requests: int
secrets_detected: int
injection_attempts: int
policy_violations: int
unique_users: int
data_volume_mb: float
average_latency_ms: float
error_rate: float
class AIToolSecurityMonitor:
def __init__(self, metrics_backend, alerting_service):
self.metrics = metrics_backend
self.alerting = alerting_service
self.thresholds = {
'blocked_request_rate': 0.05,
'injection_attempt_rate': 0.01,
'secrets_detection_rate': 0.001,
'error_rate': 0.05,
}
async def generate_security_report(
self,
tool_id: str,
period_hours: int = 24
) -> AIToolSecurityMetrics:
raw_metrics = await self.metrics.query(
tool_id=tool_id,
period_hours=period_hours
)
metrics = AIToolSecurityMetrics(
tool_id=tool_id,
period_start=raw_metrics['period_start'],
period_end=raw_metrics['period_end'],
total_requests=raw_metrics['total_requests'],
blocked_requests=raw_metrics['blocked_requests'],
secrets_detected=raw_metrics['secrets_detected'],
injection_attempts=raw_metrics['injection_attempts'],
policy_violations=raw_metrics['policy_violations'],
unique_users=raw_metrics['unique_users'],
data_volume_mb=raw_metrics['data_volume_mb'],
average_latency_ms=raw_metrics['average_latency_ms'],
error_rate=raw_metrics['error_rate'],
)
await self._check_thresholds(metrics)
return metrics
async def _check_thresholds(self, metrics: AIToolSecurityMetrics):
if metrics.total_requests == 0:
return
blocked_rate = metrics.blocked_requests / metrics.total_requests
if blocked_rate > self.thresholds['blocked_request_rate']:
await self.alerting.warn(
f"High blocked request rate for {metrics.tool_id}: {blocked_rate:.2%}"
)
injection_rate = metrics.injection_attempts / metrics.total_requests
if injection_rate > self.thresholds['injection_attempt_rate']:
await self.alerting.alert(
f"Elevated injection attempts for {metrics.tool_id}: {injection_rate:.2%}"
)
secrets_rate = metrics.secrets_detected / metrics.total_requests
if secrets_rate > self.thresholds['secrets_detection_rate']:
await self.alerting.alert(
f"High secrets exposure rate for {metrics.tool_id}: {secrets_rate:.4%}"
)Wrapping Up
Building a secure AI posture for enterprise adoption isn’t about blocking AI tools—it’s about enabling their use responsibly. The patterns I’ve outlined here have allowed our teams to adopt AI coding assistants, chat interfaces, and autonomous agents while maintaining the security and compliance posture our organization requires.
The key principles I follow:
-
Defense in depth: No single control is sufficient. Layer network controls, content filtering, RBAC, and monitoring.
-
Assume breach: Design systems expecting that prompts will contain sensitive data, agents will be compromised, and outputs will need validation.
-
Visibility first: You can’t secure what you can’t see. Comprehensive logging and monitoring are foundational.
-
Least privilege: AI agents should have the minimum permissions necessary, with JIT elevation for sensitive operations.
-
Continuous assessment: AI tools and threats evolve rapidly. Security reviews should be ongoing, not one-time gates.
The AI security landscape is still maturing. The patterns here represent what works today, but I expect them to evolve as AI capabilities expand and new threat vectors emerge. Stay curious, stay paranoid, and keep your audit logs close.