From POC to Production with AI: Avoiding Common Pitfalls
Common pitfalls when scaling AI experiments into production workflows and how to avoid them.
From POC to Production with AI: Avoiding Common Pitfalls
Too many AI projects die in the chasm between “look at this cool demo” and “this is running in production.” Having experienced this transition firsthand—and honestly, learning more from failures than successes—I’ve developed a healthy skepticism of any AI initiative that doesn’t have a production plan from day one.
Here’s what I’ve learned about why AI projects fail at productionization, and how to avoid the most common traps.
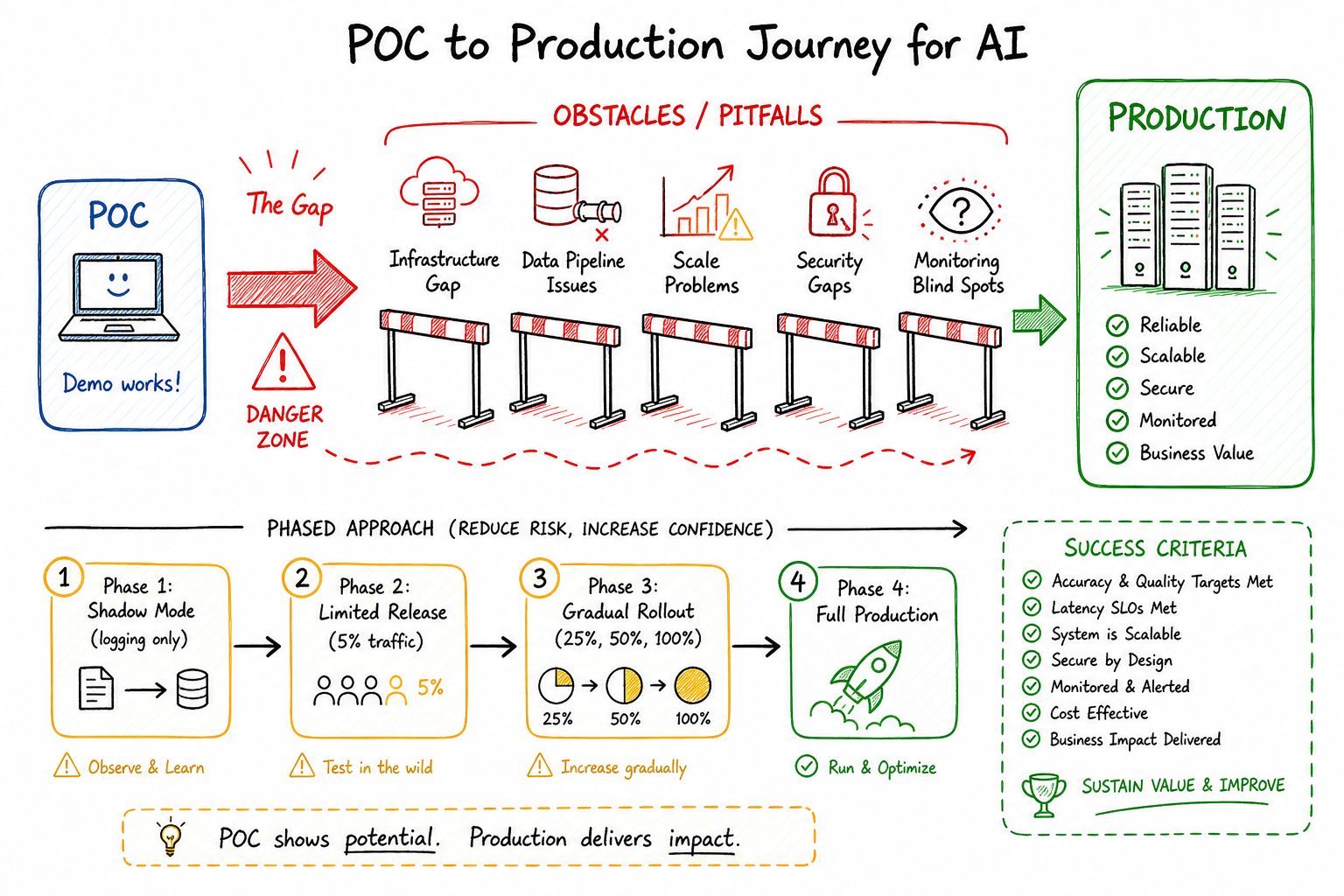
The POC Trap: Why Demos Don’t Scale
The POC trap is seductive. A data scientist spends two weeks in a Jupyter notebook, pulls some sample data, trains a model, and presents stunning results to leadership. Accuracy looks great. The demo works perfectly. Everyone’s excited.
Then reality hits.
I worked with a team that built a document classification system in three weeks. The POC processed 100 documents with 94% accuracy. Leadership greenlit production immediately. Six months later, they still hadn’t shipped. Why? The POC ran on a laptop with 64GB of RAM. Production needed to process 50,000 documents per hour. The model couldn’t fit in the memory constraints of their Kubernetes pods. The preprocessing pipeline that “just worked” with 100 documents fell over at scale. Nobody had thought about what happens when the model is wrong.
The fundamental problem: POCs are built to prove a concept. Production systems are built to run reliably under constraints. These are different engineering problems requiring different approaches.
Common Failure Patterns in AI Productionization
Based on industry post-mortems and my own experience, here are recurring patterns that kill AI projects:
The “Data Scientist Handoff” Anti-Pattern: A data scientist builds something in Python notebooks, then throws it over the wall to engineering. Engineering rewrites everything because the original code isn’t production-grade. By the time they’re done, the model is stale, the requirements have changed, and the project is six months behind.
The “Perfect Model” Trap: Teams spend months improving model accuracy from 91% to 93%, while ignoring that they have no way to deploy it, monitor it, or handle the 7% of cases where it’s wrong.
The “It Works On My Machine” Problem: The model works perfectly in the data scientist’s environment with specific library versions, CUDA drivers, and preprocessing steps that aren’t documented anywhere.
The “We’ll Figure Out Scale Later” Fallacy: Teams build for single-request inference and discover too late that their architecture can’t handle concurrent requests, batching, or the latency requirements of their users.
The “Production Data Will Look Like Training Data” Assumption: It won’t. Ever.
Infrastructure Gaps: Dev Laptop to Production Cluster
The gap between a data scientist’s laptop and a production cluster is enormous. Here’s what typically needs to change:
Compute Environment: That beefy GPU workstation becomes a fleet of inference servers with different GPU architectures, memory constraints, and networking configurations. Models that fit comfortably during development might need quantization, distillation, or architectural changes to run in production.
Dependency Management: The pip install that worked locally becomes a nightmare of conflicting CUDA versions, native library dependencies, and container image sizes. I’ve seen teams spend weeks just getting their model to build in CI.
Storage Architecture: Training data sat on a local SSD. Production needs to handle model artifacts in object storage, feature data in low-latency stores, and potentially model weights distributed across nodes.
One team I worked with had a recommendation model that required 45GB of embeddings loaded into memory. Their production pods had 16GB limits. The solution involved building a custom embedding server, sharding the embeddings, and implementing a caching layer—none of which was even considered during the POC.
Data Pipeline Challenges: Training Data vs Production Data
Training data and production data are never the same. Here’s what goes wrong:
Distribution Shift: Your model was trained on historical data. Production data reflects current behavior, which drifts over time. A fraud detection model trained on 2024 patterns might miss 2025 fraud techniques entirely.
Data Quality: Training data was cleaned, preprocessed, and curated. Production data arrives with missing fields, malformed inputs, and edge cases nobody anticipated. I’ve seen models fail because production timestamps were in a different timezone than training data.
Feature Availability: That feature that was critical for model accuracy? It requires a 15-minute computation that won’t work for real-time inference. Or it comes from a system that has 99.5% availability—which means your model can’t run 0.5% of the time.
Data Freshness: Training used batch data. Production needs streaming updates. The architecture that worked for nightly batch jobs doesn’t work when you need sub-second latency.
A retail team built a demand forecasting model using historical sales data. In production, they discovered their sales data had a 4-hour lag due to batch processing. For flash sales and promotions, the model was making predictions on stale data and performing worse than simple heuristics.
Performance at Scale: Latency, Throughput, Cost
Production AI has constraints that don’t exist in POCs:
Latency Requirements: That 500ms inference time is unacceptable for a real-time recommendation. Users expect sub-100ms responses. Achieving this might require model optimization, caching, or completely different architectures.
Throughput Demands: Processing one request at a time doesn’t scale. Production needs batching, request coalescing, and parallel processing. But naive batching increases latency. The optimization space is complex.
Cost Reality: Running inference on a p4d.24xlarge looks fine when you’re processing test data. At production scale, GPU costs can explode. I’ve seen AI projects cancelled not because they didn’t work, but because inference costs exceeded the value they provided.
One search team built a semantic search system that worked beautifully in demos. In production, they discovered that encoding queries took 50ms per request. With 1000 QPS, they needed 50 GPUs just for query encoding. The project economics didn’t work until they implemented query caching, approximate nearest neighbor search, and model distillation.
Reliability Requirements: Error Handling, Fallbacks
POCs don’t need error handling. Production systems do.
Graceful Degradation: What happens when the model service is down? When inference times out? When the model returns low-confidence results? You need fallback paths for every failure mode.
Input Validation: Production receives adversarial inputs, malformed data, and edge cases your training data never included. Robust input validation and sanitization are essential.
Circuit Breakers: When the AI service starts failing, you need to stop hammering it and fall back to alternatives. Otherwise, one struggling service takes down everything that depends on it.
Retry Logic: Transient failures happen. Smart retry logic with exponential backoff and jitter prevents cascade failures while maintaining availability.
A content moderation team shipped an AI system without fallbacks. When the model service had a brief outage, their entire content pipeline backed up. They lost 4 hours of user-generated content that had to be manually reviewed—2000 person-hours of work—because they didn’t have a “when in doubt, queue for human review” fallback.
Security Hardening for Production
AI systems introduce unique security considerations:
Model Theft: Your model represents significant IP. In production, you need to protect model weights, prevent model extraction attacks, and control access to inference endpoints.
Adversarial Inputs: Attackers can craft inputs designed to make your model behave badly. Prompt injection, adversarial examples, and data poisoning are real threats in production.
Data Leakage: Models can memorize training data. In production, this means potentially leaking sensitive information through careful queries. Privacy-preserving inference techniques may be necessary.
Supply Chain Security: AI systems have massive dependency trees. A compromised library in your ML pipeline can expose your entire infrastructure.
I consulted for a company that shipped an LLM-based customer service bot. Within a week, users discovered they could use prompt injection to make the bot reveal system prompts, internal documentation, and customer data from other sessions. The incident response cost more than the entire POC development.
Monitoring and Observability Gaps
Traditional monitoring isn’t sufficient for AI systems:
Model Performance Monitoring: Accuracy at deployment time means nothing if the model degrades over time. You need ongoing monitoring of model metrics against ground truth—which might not be available until much later.
Data Drift Detection: Input distributions change. You need automated detection of when production data no longer matches training data, before model performance degrades.
Prediction Monitoring: What is the model actually predicting? Monitoring prediction distributions can catch issues that input monitoring misses.
Business Metric Correlation: The ultimate measure is business impact. Connecting model performance to business outcomes requires thoughtful instrumentation and analysis.
A fintech company’s fraud model worked great for months, then false positives spiked 300%. Investigation revealed that a partner had changed their data format slightly—valid transactions looked anomalous to the model. They had monitoring for model latency but not for prediction distribution changes.
Team Structure and Ownership
Who owns an AI system in production? This question kills more projects than technical challenges.
The Ownership Gap: Data scientists built it, but don’t do ops. Platform engineers can run it, but don’t understand the model. Product managers own the feature, but can’t debug issues. Nobody owns the whole thing.
Cross-Functional Requirements: Production AI needs ML expertise, infrastructure skills, and domain knowledge. Teams structured around traditional boundaries struggle to provide integrated support.
On-Call Complexity: When the AI system pages at 3am, who responds? The data scientist who understands the model? The SRE who understands the infrastructure? Both?
The most successful teams I’ve seen create dedicated “ML Engineering” or “AI Platform” roles that bridge these gaps. They’re not data scientists, not traditional backend engineers, but specialists in production ML systems.
A Phased Approach to Productionization
Here’s the approach I recommend for taking AI from POC to production:
Phase 1: Shadow Mode Deploy the model alongside existing systems without affecting users. Compare AI decisions to current behavior. Measure latency, throughput, and accuracy on real production data. Duration: 2-4 weeks.
Phase 2: Limited Rollout Enable the AI system for a small percentage of traffic. Monitor closely for issues. Build confidence in reliability and performance. Enable quick rollback if problems emerge. Duration: 2-4 weeks.
Phase 3: Gradual Expansion Incrementally increase traffic to the AI system. Continue monitoring for degradation at scale. Identify and address edge cases that emerge. Duration: 4-8 weeks.
Phase 4: Full Production AI system handles all traffic with human-in-the-loop for low-confidence predictions. Continuous monitoring and regular retraining in place. Clear ownership and on-call processes established.
Skipping phases is the number one predictor of production failures I’ve observed. The team that says “we don’t need shadow mode, the POC already proved it works” is the team that has an incident in week one.
Success Criteria and Go/No-Go Decisions
Define clear criteria before starting productionization:
Technical Readiness
- Latency: p99 under target (typically 100-500ms)
- Throughput: handles expected load with headroom
- Reliability: 99.9%+ availability with fallbacks
- Cost: inference cost per request within budget
Model Performance
- Accuracy on production data within acceptable range
- Performance across all user segments (not just averages)
- Drift detection and alerting in place
- Retraining pipeline operational
Operational Readiness
- Runbooks for common failure modes
- On-call rotation established
- Escalation paths clear
- Rollback tested and documented
Business Alignment
- Success metrics defined and instrumented
- Failure impact understood and accepted
- Human review processes for edge cases
- Customer communication plan for errors
The go/no-go decision should be based on evidence, not hope. Every criterion should have measurable thresholds. “The model is good enough” is not a go decision—“the model achieves 92% accuracy on production data, exceeding our 90% threshold, with p99 latency of 87ms” is.
Conclusion
The gap between AI POC and production isn’t a gap—it’s a chasm. Crossing it requires acknowledging that productionization is its own engineering discipline with its own challenges, distinct from model development.
The teams that succeed treat production readiness as a first-class concern from day one. They build with constraints in mind. They plan for failure. They measure everything. They ship incrementally and learn from production.
The teams that fail treat production as someone else’s problem, to be figured out after the model is “done.”
AI is powerful, but only if it runs reliably in production. The best model in the world is worthless if it can’t serve users. Start with the end in mind, plan for the hard parts, and don’t let the excitement of a successful POC blind you to the work that remains.
The path from POC to production is long. But with the right approach, it doesn’t have to be a death march.