AI Golden Paths for Engineering Teams
How to build standardized, secure workflows for AI tool adoption with scoped access, sandboxes, and approval gates.
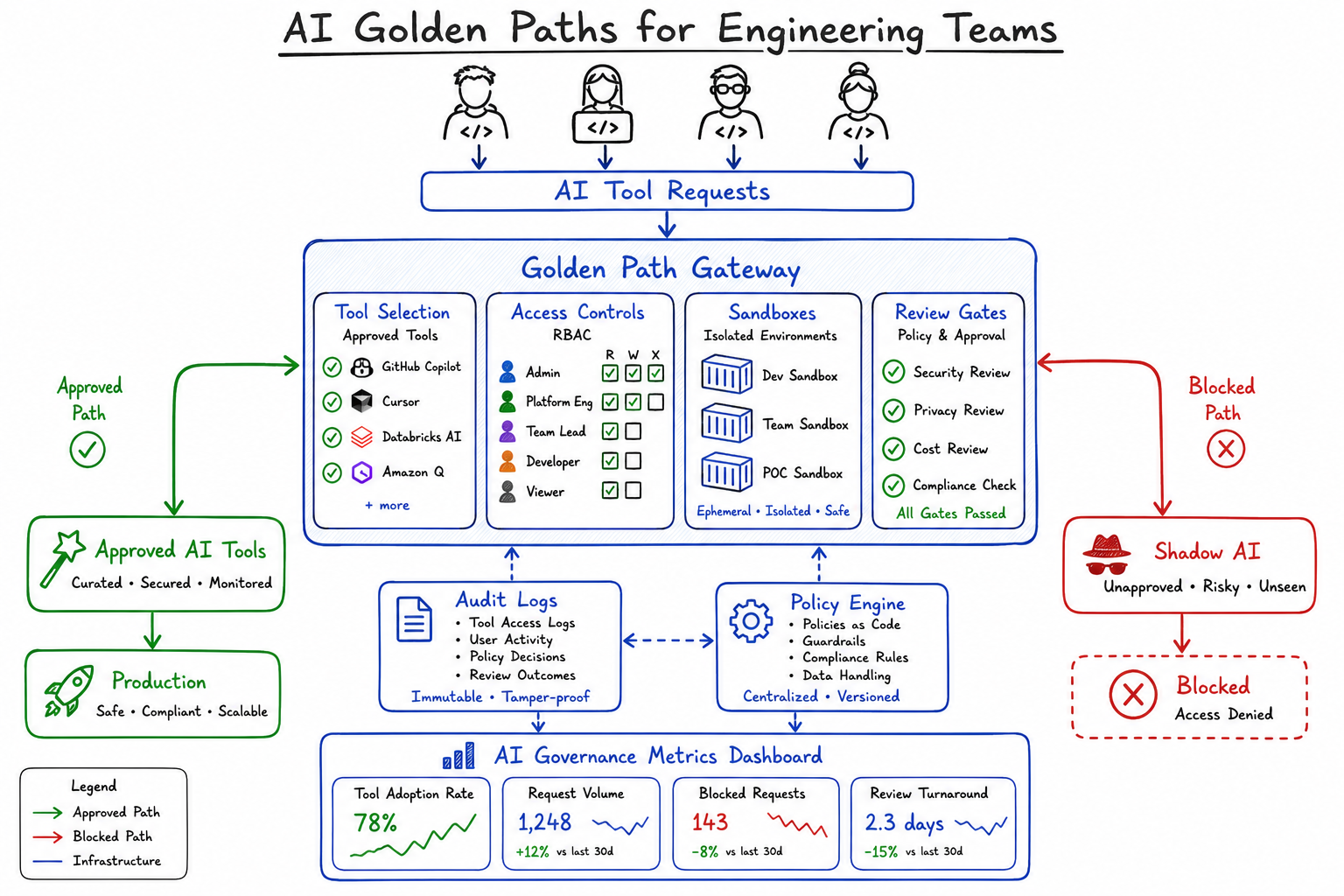
As a platform engineer, I’ve watched teams struggle with AI tool adoption over the past two years. The pattern is always the same: a few developers start using ChatGPT or Copilot, then someone spins up an internal LLM, another team builds a RAG pipeline, and suddenly you have fifteen different AI integrations with no governance, inconsistent security postures, and zero visibility into what’s being sent where.
This is where golden paths come in.
What Are Golden Paths and Why They Matter
Golden paths are opinionated, supported workflows that make the right way the easy way. The concept comes from Spotify’s platform engineering philosophy—instead of blocking developers from doing things, you pave a well-lit road that’s faster and safer than cutting through the woods.
For AI adoption, a golden path means providing pre-approved tools, secure integrations, and clear guardrails so teams can move fast without creating security incidents or compliance nightmares.
The alternative—letting every team figure out AI tooling themselves—leads to:
- Sensitive code and data leaking to public APIs
- Shadow IT sprawl that security can’t monitor
- Duplicated effort across teams building similar integrations
- No audit trail when something goes wrong
The Risks of Uncontrolled AI Tool Sprawl
I worked with a fintech company last year that discovered developers had been pasting customer transaction data into Claude to help debug issues. Nobody had malicious intent—they just wanted to move faster. But that data included PII, and now there’s a compliance incident.
The risks fall into several categories:
Data exfiltration: Every prompt sent to a public AI API is potential data leakage. Code, configuration, logs, customer data—developers paste whatever helps them solve the problem.
Supply chain attacks: AI-generated code can introduce vulnerabilities. Without review gates, that code goes straight to production.
Cost explosion: Untracked API usage adds up. I’ve seen teams burn through $50k in OpenAI credits in a month because there was no budget enforcement.
Compliance violations: GDPR, HIPAA, SOC2—all have requirements around data handling that casual AI usage can violate.
Inconsistent quality: When every team uses different tools with different prompts, you get inconsistent outputs and no way to improve systematically.
Components of an AI Golden Path
A well-designed AI golden path has four core components: tool selection, access controls, sandboxed environments, and review gates.
Tool Selection
Start by defining which AI tools are approved for which use cases. This isn’t about restricting choice—it’s about reducing cognitive load and ensuring security review.
# ai-tools-policy.yaml
approved_tools:
code_generation:
- name: "GitHub Copilot Business"
approved_for: ["all_repositories"]
data_classification: ["public", "internal"]
- name: "Internal CodeLLM"
approved_for: ["all_repositories"]
data_classification: ["public", "internal", "confidential"]
chat_assistants:
- name: "Azure OpenAI (internal deployment)"
approved_for: ["general_queries", "code_review", "documentation"]
data_classification: ["public", "internal"]
not_approved:
- name: "ChatGPT (public)"
reason: "No data retention guarantees"
- name: "Claude (public API)"
reason: "Use internal proxy instead"Access Controls
Not everyone needs access to everything. Implement RBAC that matches your data classification levels.
# terraform/ai-access-controls.tf
resource "aws_iam_policy" "ai_developer_access" {
name = "ai-developer-access"
description = "Standard developer access to AI services"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
]
Resource = [
"arn:aws:bedrock:*:*:model/anthropic.claude-3-sonnet*",
"arn:aws:bedrock:*:*:model/amazon.titan-text*"
]
Condition = {
StringEquals = {
"aws:RequestTag/environment": "development"
}
}
}
]
})
}
resource "aws_iam_policy" "ai_elevated_access" {
name = "ai-elevated-access"
description = "Access to more capable models for senior engineers"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
]
Resource = [
"arn:aws:bedrock:*:*:model/anthropic.claude-3-opus*",
"arn:aws:bedrock:*:*:model/anthropic.claude-3-sonnet*"
]
}
]
})
}Sandboxed Environments
AI-generated code should never go straight to production. Create isolated environments where developers can test AI outputs safely.
# .github/workflows/ai-sandbox.yaml
name: AI Code Sandbox
on:
pull_request:
paths:
- '**/*.ai-generated.*'
- '**/ai-suggestions/**'
jobs:
sandbox-test:
runs-on: ubuntu-latest
environment: ai-sandbox
steps:
- uses: actions/checkout@v4
- name: Detect AI-generated code
id: detect
run: |
# Check for AI generation markers
if git diff --name-only origin/main | xargs grep -l "AI-GENERATED\|copilot\|Generated by"; then
echo "ai_code_detected=true" >> $GITHUB_OUTPUT
fi
- name: Run security scan
if: steps.detect.outputs.ai_code_detected == 'true'
uses: github/codeql-action/analyze@v3
with:
category: ai-generated-code
- name: Run in isolated container
if: steps.detect.outputs.ai_code_detected == 'true'
run: |
docker run --rm \
--network none \
--memory 512m \
--cpus 0.5 \
-v ${{ github.workspace }}:/app:ro \
ai-sandbox-runner:latest \
/app/test.shReview Gates
Automated checks are necessary but not sufficient. Build human review into the process for high-risk changes.
# scripts/ai_review_gate.py
import os
import sys
from github import Github
REVIEW_THRESHOLDS = {
"lines_changed": 100,
"files_changed": 5,
"sensitive_paths": [
"src/auth/",
"src/payments/",
"infrastructure/",
"*.env*"
]
}
def requires_human_review(pr_files, pr_stats):
"""Determine if AI-generated changes need human review."""
if pr_stats["additions"] + pr_stats["deletions"] > REVIEW_THRESHOLDS["lines_changed"]:
return True, "Large change set requires review"
if len(pr_files) > REVIEW_THRESHOLDS["files_changed"]:
return True, "Many files modified"
for file in pr_files:
for sensitive in REVIEW_THRESHOLDS["sensitive_paths"]:
if fnmatch.fnmatch(file.filename, sensitive):
return True, f"Sensitive path modified: {file.filename}"
return False, None
def main():
gh = Github(os.environ["GITHUB_TOKEN"])
repo = gh.get_repo(os.environ["GITHUB_REPOSITORY"])
pr = repo.get_pull(int(os.environ["PR_NUMBER"]))
needs_review, reason = requires_human_review(
pr.get_files(),
{"additions": pr.additions, "deletions": pr.deletions}
)
if needs_review:
pr.create_review_request(reviewers=["security-team"])
pr.create_issue_comment(
f"🤖 AI-generated code review required: {reason}\n\n"
"A security team member must approve before merge."
)
sys.exit(1)
if __name__ == "__main__":
main()Implementation Patterns
RBAC for AI Resources
Map your existing role hierarchy to AI capabilities. Here’s a pattern I’ve used successfully:
# platform/ai-rbac.yaml
roles:
developer:
ai_capabilities:
- code_completion
- documentation_generation
- test_generation
model_tier: "standard"
monthly_budget_usd: 50
data_classification_max: "internal"
senior_developer:
ai_capabilities:
- code_completion
- documentation_generation
- test_generation
- architecture_suggestions
- code_review
model_tier: "advanced"
monthly_budget_usd: 200
data_classification_max: "confidential"
ml_engineer:
ai_capabilities:
- all
model_tier: "advanced"
monthly_budget_usd: 500
data_classification_max: "confidential"
fine_tuning_allowed: trueAudit Logging
Every AI interaction should be logged. Not the full prompts (that creates its own data retention issues), but enough metadata to reconstruct what happened.
# middleware/ai_audit_logger.py
import hashlib
import json
from datetime import datetime
from dataclasses import dataclass, asdict
@dataclass
class AIAuditEvent:
timestamp: str
user_id: str
team: str
tool: str
model: str
action: str
prompt_hash: str # SHA256, not the actual prompt
prompt_length: int
response_length: int
tokens_used: int
cost_usd: float
data_classification: str
repository: str | None
success: bool
error_type: str | None
class AIAuditLogger:
def __init__(self, sink):
self.sink = sink
def log_interaction(self, user, tool, model, prompt, response, metadata):
event = AIAuditEvent(
timestamp=datetime.utcnow().isoformat(),
user_id=user.id,
team=user.team,
tool=tool,
model=model,
action=metadata.get("action", "unknown"),
prompt_hash=hashlib.sha256(prompt.encode()).hexdigest(),
prompt_length=len(prompt),
response_length=len(response) if response else 0,
tokens_used=metadata.get("tokens", 0),
cost_usd=metadata.get("cost", 0.0),
data_classification=metadata.get("classification", "unknown"),
repository=metadata.get("repository"),
success=metadata.get("success", True),
error_type=metadata.get("error_type")
)
self.sink.write(json.dumps(asdict(event)))Policy Gates with OPA
Use Open Policy Agent to enforce AI usage policies declaratively:
# policies/ai_usage.rego
package ai.usage
default allow = false
# Allow standard developers to use approved models
allow {
input.user.role == "developer"
input.model in approved_models
input.data_classification in ["public", "internal"]
within_budget(input.user.id, input.estimated_cost)
}
# Allow senior developers more capabilities
allow {
input.user.role == "senior_developer"
input.model in advanced_models
input.data_classification in ["public", "internal", "confidential"]
within_budget(input.user.id, input.estimated_cost)
}
approved_models = {
"claude-3-sonnet",
"gpt-4-turbo",
"titan-text-express"
}
advanced_models = approved_models | {
"claude-3-opus",
"gpt-4o"
}
within_budget(user_id, cost) {
spent := data.usage[user_id].monthly_spend
limit := data.budgets[user_id].monthly_limit
spent + cost <= limit
}
# Deny if sensitive data patterns detected
deny[msg] {
contains_pii(input.prompt)
msg := "Prompt appears to contain PII"
}
deny[msg] {
contains_secrets(input.prompt)
msg := "Prompt appears to contain secrets"
}Balancing Developer Velocity with Security
The hardest part of golden paths is avoiding the “paved road to nowhere” problem. If your golden path is slower or more painful than the alternative, developers will route around it.
Here’s how I approach the balance:
Make the golden path faster, not just safer. Pre-configured IDE extensions, cached model responses for common queries, team-specific fine-tuning—the secure option should also be the productive option.
Provide escape hatches with accountability. Sometimes developers need to go off-path. Let them, but require explicit justification and extra review.
# .ai-override.yaml (must be approved by security team)
override:
reason: "Evaluating new model for specific use case"
approved_by: "security-team"
expires: "2025-06-01"
restrictions:
- "No production data"
- "Results must be reviewed before use"
audit_level: "verbose"Iterate based on friction reports. Track where developers hit roadblocks and address them systematically.
Communicate the why. Developers are more likely to follow guidelines when they understand the reasoning. Share anonymized incident reports, explain the compliance requirements, make the risks concrete.
Metrics for Measuring Golden Path Adoption
You can’t improve what you don’t measure. Here are the metrics I track for AI golden path programs:
Adoption Metrics
-- Golden path adoption rate
SELECT
team,
COUNT(CASE WHEN tool IN (SELECT name FROM approved_tools) THEN 1 END) as approved_usage,
COUNT(*) as total_usage,
ROUND(100.0 * COUNT(CASE WHEN tool IN (SELECT name FROM approved_tools) THEN 1 END) / COUNT(*), 2) as adoption_rate
FROM ai_audit_log
WHERE timestamp > CURRENT_DATE - INTERVAL '30 days'
GROUP BY team
ORDER BY adoption_rate DESC;Security Metrics
- Policy violations caught: How many times did gates prevent problematic usage?
- Mean time to remediation: When issues are found, how quickly are they fixed?
- Data classification accuracy: Are developers correctly classifying their data?
Productivity Metrics
- Time from request to access: How long does it take to get approved for AI tools?
- Developer satisfaction scores: Are developers happy with the available tools?
- Support ticket volume: Are people confused about what’s allowed?
Cost Metrics
# reports/ai_cost_dashboard.py
def generate_cost_report(audit_logs):
return {
"total_spend": sum(log.cost_usd for log in audit_logs),
"spend_by_team": aggregate_by(audit_logs, "team", "cost_usd"),
"spend_by_model": aggregate_by(audit_logs, "model", "cost_usd"),
"cost_per_developer": total_spend / unique_users,
"budget_utilization": {
team: spent / budget
for team, spent in spend_by_team.items()
},
"projected_monthly": extrapolate_to_month(audit_logs)
}Getting Started
If you’re building an AI golden path from scratch, here’s my recommended sequence:
-
Inventory current usage. You can’t govern what you don’t know exists. Survey teams, check expense reports for AI subscriptions, review network logs.
-
Define data classification. Before you can set policies, you need agreement on what data can go where.
-
Start with one tool. Pick the highest-impact AI tool (usually code completion) and build a complete golden path for it before expanding.
-
Instrument everything. Get audit logging in place early. You’ll need the data to justify future investments.
-
Create feedback loops. Make it easy for developers to report friction and suggest improvements.
-
Iterate publicly. Share adoption metrics, celebrate wins, acknowledge gaps. Transparency builds trust.
The goal isn’t to control developers—it’s to make AI adoption sustainable. A good golden path makes secure usage the path of least resistance, so teams can move fast without creating risk. That’s the balance we’re all trying to strike.